Bonjour à tous,
Tout d’abord, je voulais vous remercier de m’accueillir sur votre forum. J’utilise R de plus en plus mais je reste une débutante.
Mon problème est le suivant, je cherche à expliquer les causes d’un échec massif à un examen de première année de licence dont l’épreuve était classiquement noté de 0 à 20. Il y avait au total 385 étudiants qui ont passé l’épreuve.
Au cours de l’année, les étudiants avaient la possibilité de rendre des devoirs qui étaient facultatifs, il y avait deux devoirs de prévus. J’ai ainsi constitué 3 groupes de sujets en fonction du nombre de devoirs rendus durant l’année :
- Groupe zéro (aucun devoir rendu) : n =207
- Groupe un (un seul devoir rendu) : n = 42
- Groupe deux (deux devoirs rendus) : n = 136
Comme vous le constatez, les groupes sont très déséquilibrés. La variable réponse ici, c’est donc la note obtenue à l’examen : variable « note1 » (note de 0 à 20). Le facteur, c’est le « groupe » (zéro, un deux).
J’ai testé 2 modèles :
Étant donnée qu’une note de 0 à 20, n’est pas vraiment une variable continue et que d’autre part, les distributions obtenues étaient fortement biaisées (vers les notes très faibles), j’ai testé deux types de modèles :
J’ai d’abord utilisé le modèle linéaire généralisé avec une structure d’erreur en quasi poisson à cause de la surdispersion qui apparaît souvent avec ce genre de données (model1). J’ai ensuite testé un modèle avec une erreur en binomial inverse grâce à la fonction glm.nb (model2). Dans les deux cas, on obtient une différence significative entre le « groupzéro » et l’intercept c’est-à-dire le « groupedeux ». Malheureusement, il me semble que mes deux modèles ne se comportent pas très bien si j’en juge les graphiques diagnostiques que j’obtiens dans les deux situations (pardonnez_moi, mais je n'arrive pas à afficher sur le forum les graphiques en question).
J’en viens à présent à mes questions : Que pensez-vous de mon analyse ? Ai-je le droit de faire ce que j’ai fait avec des groupes aussi déséquilibrés ?
Y a-t-il d’autres méthodes pour analyser ce genre de données ?
Merci pour vos réponses
glm avec erreur en quasipoisson ou glm.nb ?
Modérateur : Groupe des modérateurs
-
Lorraine Bauer
- Messages : 67
- Enregistré le : 18 Nov 2008, 12:06
-
Renaud Lancelot
- Messages : 2484
- Enregistré le : 16 Déc 2004, 08:01
- Contact :
Re: glm avec erreur en quasipoisson ou glm.nb ?
Lorraine Bauer a écrit :Bonjour à tous,
Tout d’abord, je voulais vous remercier de m’accueillir sur votre forum. J’utilise R de plus en plus mais je reste une débutante.
Mon problème est le suivant, je cherche à expliquer les causes d’un échec massif à un examen de première année de licence dont l’épreuve était classiquement noté de 0 à 20. Il y avait au total 385 étudiants qui ont passé l’épreuve.
Au cours de l’année, les étudiants avaient la possibilité de rendre des devoirs qui étaient facultatifs, il y avait deux devoirs de prévus. J’ai ainsi constitué 3 groupes de sujets en fonction du nombre de devoirs rendus durant l’année :
- Groupe zéro (aucun devoir rendu) : n =207
- Groupe un (un seul devoir rendu) : n = 42
- Groupe deux (deux devoirs rendus) : n = 136
Comme vous le constatez, les groupes sont très déséquilibrés. La variable réponse ici, c’est donc la note obtenue à l’examen : variable « note1 » (note de 0 à 20). Le facteur, c’est le « groupe » (zéro, un deux).
J’ai testé 2 modèles :
Étant donnée qu’une note de 0 à 20, n’est pas vraiment une variable continue
Beaucoup de gens ne s'arrêtent pas à ce "détail" et utilisent la distribution gaussienne (il est de plus fréquent que les notes puissent prendre des valeurs intermédiaires entre les entiers).
et que d’autre part, les distributions obtenues étaient fortement biaisées (vers les notes très faibles), j’ai testé deux types de modèles :
J’ai d’abord utilisé le modèle linéaire généralisé avec une structure d’erreur
Attention, erreur de concept fréquemment commise: c'est la réponse qui suit une loi de Poisson (ou adaptation quasi-Poisson), et non l'erreur résiduelle.
en quasi poisson à cause de la surdispersion qui apparaît souvent avec ce genre de données (model1). J’ai ensuite testé un modèle avec une erreur en binomial inverse grâce à la fonction glm.nb (model2).
Essayer la fonction gamlss du package de même nom: converge bcp plus rapidement et de manière plus fiable que glm.nb
Dans les deux cas, on obtient une différence significative entre le « groupzéro » et l’intercept c’est-à-dire le « groupedeux ». Malheureusement, il me semble que mes deux modèles ne se comportent pas très bien si j’en juge les graphiques diagnostiques que j’obtiens dans les deux situations (pardonnez_moi, mais je n'arrive pas à afficher sur le forum les graphiques en question).
Il faut les héberger sur un site http ou ftp et donner l'adresse. Si vous n'avez pas d'accès, je peux le faire pour vous.
J’en viens à présent à mes questions : Que pensez-vous de mon analyse ? Ai-je le droit de faire ce que j’ai fait avec des groupes aussi déséquilibrés ?
Ce n'est pas le pb ici: les méthodes que vous avez utilisées sont adaptées pour des plans déséquilibrés.
Y a-t-il d’autres méthodes pour analyser ce genre de données ?
Merci pour vos réponses
Pas sûr que vous arriviez à des résultats satisfaisants avec ces lois.
(1) Essayer avec un modèle gaussien pour lequel il n'y a pas de relation entre moyenne et variance.
(2) Si vous avez beaucoup de 0's à la note finale, vous pouvez essayer un modèle avec excès de 0's. Voir par exemple le package pscl et la documentation associée, y compris article de Zeileis:
@ARTICLE{Zeileis2008,
author = {Zeileis, A. and Kleiber, C. and Jackman, S.},
title = {{Regression models for count data in R}},
journal = {Journal of Statistical Software},
year = {2008},
volume = {27},
pages = {1--25},
number = {8},
month = {July},
abstract = {The classical Poisson, geometric and negative binomial regression
models for count data belong to the family of generalized linear
models and are available at the core of the statistics toolbox in
the R system for statistical computing. After reviewing the conceptual
and computational features of these methods, a new implementation
of hurdle and zero-inflated regression models in the functions hurdle()
and zeroinfl() from the package pscl is introduced. It re-uses design
and functionality of the basic R functions just as the underlying
conceptual tools extend the classical models. Both hurdle and zero-inflated model, are able to incorporate over-dispersion and excess zeros-two problems that typically occur in count data sets in economics and
the social sciences—better than their classical counterparts. Using
cross-section data on the demand for medical care, it is illustrated
how the classical as well as the zero-augmented models can be fitted,
inspected and tested in practice.},
url = {http://www.jstatsoft.org/v27/i08}
}
(3) Essayer un glm avec une distribution Gamma.
Renaud
-
Eric Pagot
- Messages : 195
- Enregistré le : 15 Fév 2007, 17:10
-
Lorraine Bauer
- Messages : 67
- Enregistré le : 18 Nov 2008, 12:06
Bonjour et merci pour tous vos commentaires et suggestions. Pour le Kruskall-Wallis, c’est vrai que je n’y avais pas pensé, je testerai cette solution également pour voir ce que cela donne.
En revanche, Renaud, je crois que vous m’avez donné un sérieux éclairage en me conseillant de regarder du côté de la fonction gamlss que je ne connaissais pas ! J’ai pris sur le site dédié à cette fonction toute la doc que j’ai pu télécharger, je vais étudier cela prochainement.
Bon d’abord au sujet de mon erreur conceptuelle, c’est effectivement la variable réponse qui suit une des lois de probabilité dont nous parlons ici. Ce point reste problématique pour moi, car dans ce que j’ai déjà pu lire on parle souvent de différents types d’ « error structure ». Bref si je comprends bien, il faut se débrouiller pour trouver un modèle qui « colle » avec la distribution de la réponse et lorsque on a trouvé un tel model, la loi qui est sous-jacente à l’erreur tend à se rapprocher d’une loi normale. Ce qui me pose alors problème, c’est ce terme d’ « error structure », je ne comprends pas très bien le type de rapport qui existe entre la loi de proba sous-jacente à la variable réponse et la loi sous-jacente à l’erreur…
Pour en revenir à mes données et à la fonction gamlss, je crois que j’ai trouvé un modèle très satisfaisant (modèle 4 et 5, voir plus bas). Pour illustrer la discussion, j’ai mis en ligne comme vous me l’avez suggéré mes documents.
Vous trouverez ici http://docs.google.com/Doc?id=dhksgr6k_10f2fd5wdf mon jeu de données. Les notes des étudiants étant des notes variant de 0 à 20, il n’y a pas de demi-points, ce sont uniquement des entiers. Avec l’allure des distributions obtenues dans les trois groupes, c’est une des raisons qui m’a conduit à passer au modèle linéaire généralisé.
Ici http://docs.google.com/Doc?id=dhksgr6k_11c74bjtfz le graphique des distributions
Ici http://docs.google.com/View?docid=dhksgr6k_13dzppwng8&hl=fr le graphique des moyennes et les boite à moustaches correspondantes
Ensuite http://docs.google.com/Doc?id=dhksgr6k_8dw8wg3f3 les graphiques diagnostiques de mon premier modèle :
model1<-glm(note1~groupe,quasipoisson)
Ici http://docs.google.com/Doc?id=dhksgr6k_6dv33trcs le graphique diagnostique de mon second modèle :
model2<-glm.nb(note1~groupe)
Ici http://docs.google.com/Doc?id=dhksgr6k_4cwkb23cs les graphiques diagnostiques du troisième modèle que j’ai réalisé avec la fonction gamlss que vous m’avez conseillée.
model3<-gamlss(note1~groupe)
GAMLSS-RS iteration 1: Global Deviance = 2005.669
GAMLSS-RS iteration 2: Global Deviance = 2005.669
Ici http://docs.google.com/Doc?id=dhksgr6k_0g78655dt les graphiques de mon modèle numéro 4 avec une réponse en binomiale négative de type 1
> NBI()
GAMLSS Family: NBI Negative Binomial type I
Link function for mu : log
Link function for sigma: log
> model4<-gamlss(note1~groupe,family=NBI)
GAMLSS-RS iteration 1: Global Deviance = 1784.607
GAMLSS-RS iteration 2: Global Deviance = 1784.607
Ici http://docs.google.com/Doc?id=dhksgr6k_2fjmxwhdj les graphiques de mon modèle numéro 5 en binomiale négative de type 2
> NBII()
GAMLSS Family: NBII Negative Binomial type II
Link function for mu : log
Link function for sigma: log
> model5<-gamlss(note1~groupe,family=NBII)
GAMLSS-RS iteration 1: Global Deviance = 1776.433
GAMLSS-RS iteration 2: Global Deviance = 1776.406
GAMLSS-RS iteration 3: Global Deviance = 1776.405[url][/url]
Voilà, il me semble que les deux derniers-modèles sont parfaits. Qu’en pensez-vous ?
Concernant les graphiques diagnostique de la fonction gamlss, je réfléchis principalement sur les 2 graphiques du bas et sur celui du haut à gauche, en revanche le graphique du haut à droite « quantile résiduals » contre « index », je ne le comprends pas vraiment, je ne sais pas si vous pouvez un petit peu m’éclairer sur son interprétation.
Encore une fois merci pour votre très précieuse aide et expertise
Lorraine
En revanche, Renaud, je crois que vous m’avez donné un sérieux éclairage en me conseillant de regarder du côté de la fonction gamlss que je ne connaissais pas ! J’ai pris sur le site dédié à cette fonction toute la doc que j’ai pu télécharger, je vais étudier cela prochainement.
Bon d’abord au sujet de mon erreur conceptuelle, c’est effectivement la variable réponse qui suit une des lois de probabilité dont nous parlons ici. Ce point reste problématique pour moi, car dans ce que j’ai déjà pu lire on parle souvent de différents types d’ « error structure ». Bref si je comprends bien, il faut se débrouiller pour trouver un modèle qui « colle » avec la distribution de la réponse et lorsque on a trouvé un tel model, la loi qui est sous-jacente à l’erreur tend à se rapprocher d’une loi normale. Ce qui me pose alors problème, c’est ce terme d’ « error structure », je ne comprends pas très bien le type de rapport qui existe entre la loi de proba sous-jacente à la variable réponse et la loi sous-jacente à l’erreur…
Pour en revenir à mes données et à la fonction gamlss, je crois que j’ai trouvé un modèle très satisfaisant (modèle 4 et 5, voir plus bas). Pour illustrer la discussion, j’ai mis en ligne comme vous me l’avez suggéré mes documents.
Vous trouverez ici http://docs.google.com/Doc?id=dhksgr6k_10f2fd5wdf mon jeu de données. Les notes des étudiants étant des notes variant de 0 à 20, il n’y a pas de demi-points, ce sont uniquement des entiers. Avec l’allure des distributions obtenues dans les trois groupes, c’est une des raisons qui m’a conduit à passer au modèle linéaire généralisé.
Ici http://docs.google.com/Doc?id=dhksgr6k_11c74bjtfz le graphique des distributions
Ici http://docs.google.com/View?docid=dhksgr6k_13dzppwng8&hl=fr le graphique des moyennes et les boite à moustaches correspondantes
Ensuite http://docs.google.com/Doc?id=dhksgr6k_8dw8wg3f3 les graphiques diagnostiques de mon premier modèle :
model1<-glm(note1~groupe,quasipoisson)
Ici http://docs.google.com/Doc?id=dhksgr6k_6dv33trcs le graphique diagnostique de mon second modèle :
model2<-glm.nb(note1~groupe)
Ici http://docs.google.com/Doc?id=dhksgr6k_4cwkb23cs les graphiques diagnostiques du troisième modèle que j’ai réalisé avec la fonction gamlss que vous m’avez conseillée.
model3<-gamlss(note1~groupe)
GAMLSS-RS iteration 1: Global Deviance = 2005.669
GAMLSS-RS iteration 2: Global Deviance = 2005.669
Ici http://docs.google.com/Doc?id=dhksgr6k_0g78655dt les graphiques de mon modèle numéro 4 avec une réponse en binomiale négative de type 1
> NBI()
GAMLSS Family: NBI Negative Binomial type I
Link function for mu : log
Link function for sigma: log
> model4<-gamlss(note1~groupe,family=NBI)
GAMLSS-RS iteration 1: Global Deviance = 1784.607
GAMLSS-RS iteration 2: Global Deviance = 1784.607
Ici http://docs.google.com/Doc?id=dhksgr6k_2fjmxwhdj les graphiques de mon modèle numéro 5 en binomiale négative de type 2
> NBII()
GAMLSS Family: NBII Negative Binomial type II
Link function for mu : log
Link function for sigma: log
> model5<-gamlss(note1~groupe,family=NBII)
GAMLSS-RS iteration 1: Global Deviance = 1776.433
GAMLSS-RS iteration 2: Global Deviance = 1776.406
GAMLSS-RS iteration 3: Global Deviance = 1776.405[url][/url]
Voilà, il me semble que les deux derniers-modèles sont parfaits. Qu’en pensez-vous ?
Concernant les graphiques diagnostique de la fonction gamlss, je réfléchis principalement sur les 2 graphiques du bas et sur celui du haut à gauche, en revanche le graphique du haut à droite « quantile résiduals » contre « index », je ne le comprends pas vraiment, je ne sais pas si vous pouvez un petit peu m’éclairer sur son interprétation.
Encore une fois merci pour votre très précieuse aide et expertise
Lorraine
-
jean lobry
- Messages : 733
- Enregistré le : 17 Jan 2008, 20:00
- Contact :
Bonjour Lorraine,
pour une débutante sous R tu ne te débrouilles pas trop mal ! Tes données sont déjà accessibles pour que l'on puisse jouer avec, et tu as commis une belle collection de graphiques qui résument bien la triste situation.
Je n'ai pas le temps tout de suite de me pencher sur tes données mais je vais essayer plus tard. La seule chose que je puisse dire pour le moment c'est qu'il me semble que tu manque de recul sur ton jeu de données : la seule variable explicative est une estimation de la motivation des étudiants, on va trouver des trivialités du genre "les étudiants motivés ont les meilleures notes". Pas la peine de faire des stats sophistiquées pour ça (un simple graphique suffit). Mais il y a bien des choses orthogonales à la question initiale que tu devrais pouvoir tirer de ce jeu de données.
Amicalement,
Jean
pour une débutante sous R tu ne te débrouilles pas trop mal ! Tes données sont déjà accessibles pour que l'on puisse jouer avec, et tu as commis une belle collection de graphiques qui résument bien la triste situation.
Je n'ai pas le temps tout de suite de me pencher sur tes données mais je vais essayer plus tard. La seule chose que je puisse dire pour le moment c'est qu'il me semble que tu manque de recul sur ton jeu de données : la seule variable explicative est une estimation de la motivation des étudiants, on va trouver des trivialités du genre "les étudiants motivés ont les meilleures notes". Pas la peine de faire des stats sophistiquées pour ça (un simple graphique suffit). Mais il y a bien des choses orthogonales à la question initiale que tu devrais pouvoir tirer de ce jeu de données.
Amicalement,
Jean
-
Lorraine Bauer
- Messages : 67
- Enregistré le : 18 Nov 2008, 12:06
Bonjour Jean,
Merci de votre aide et merci de me consacrer un peu de votre temps. En ce qui concerne mes données je sais qu’il y a un côté trivial dans ce que j’observe là, mais justement c’est aussi cela qui m’intéresse car cette affaire d’examen catastrophique a suscité beaucoup de passions chez certains enseignants (et chez certains étudiants) et j’ai aussi entendu beaucoup d’explications assez alambiquées au sujet de cette affaire. J’aimerais bien avoir un solide argument (statistique) pour recadrer un peu les choses et revenir à des explications de bon sens. J’ai aussi tenté d’aller plus loin en croisant d’autres données avec celles-ci, mais hélas, je n’ai pas les autorisations nécessaires pour entreprendre ce travail.
En tout cas, je suis très avide des commentaires que l’on peut me faire ici car, je dois aussi dire que j’ai très envie de progresser à la fois conceptuellement dans la compréhension des statistiques et dans l’usage que je peux avoir de R.
A bientôt
Lorraine
Merci de votre aide et merci de me consacrer un peu de votre temps. En ce qui concerne mes données je sais qu’il y a un côté trivial dans ce que j’observe là, mais justement c’est aussi cela qui m’intéresse car cette affaire d’examen catastrophique a suscité beaucoup de passions chez certains enseignants (et chez certains étudiants) et j’ai aussi entendu beaucoup d’explications assez alambiquées au sujet de cette affaire. J’aimerais bien avoir un solide argument (statistique) pour recadrer un peu les choses et revenir à des explications de bon sens. J’ai aussi tenté d’aller plus loin en croisant d’autres données avec celles-ci, mais hélas, je n’ai pas les autorisations nécessaires pour entreprendre ce travail.
En tout cas, je suis très avide des commentaires que l’on peut me faire ici car, je dois aussi dire que j’ai très envie de progresser à la fois conceptuellement dans la compréhension des statistiques et dans l’usage que je peux avoir de R.
A bientôt
Lorraine
-
jean lobry
- Messages : 733
- Enregistré le : 17 Jan 2008, 20:00
- Contact :
Bonjour Lorraine,
tu es est en train de faire ce que l'on appelle de l'analyse de données post-mortem, ce n'est pas une position toujours très confortable. J'ai regardé tes données de plus près :
ce qui nous donne :
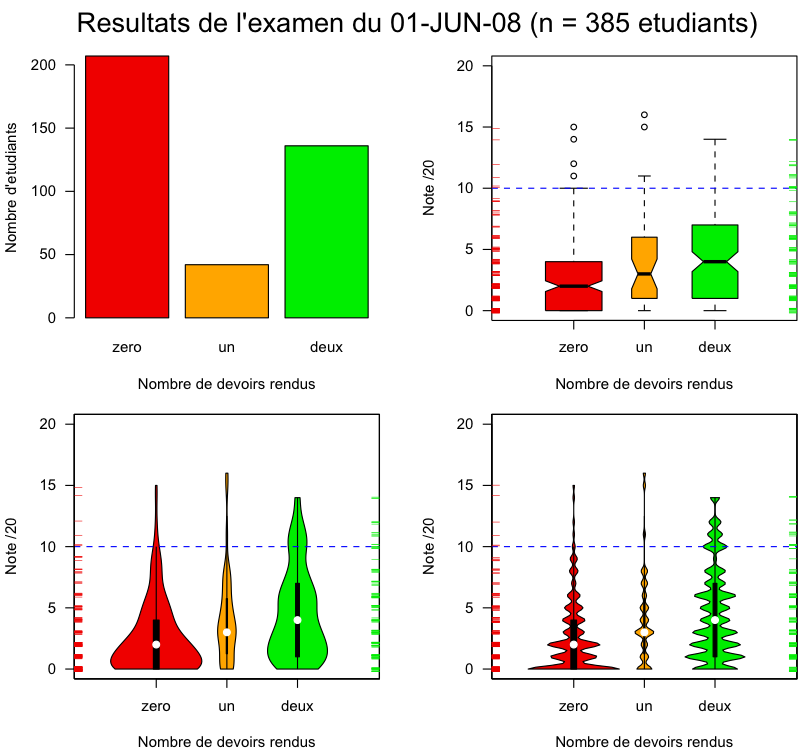
Pour moi le plus surprenant est qu'il n'y ait que 35 % des étudiants qui aient profité de la possibilité de rendre 2 devoirs, cela fait une proportion de touristes inhabituellement élevée, même pour une première année de licence.
Amicalement,
Jean
tu es est en train de faire ce que l'on appelle de l'analyse de données post-mortem, ce n'est pas une position toujours très confortable. J'ai regardé tes données de plus près :
Code : Tout sélectionner
n1j <- read.table("http://pbil.univ-lyon1.fr/R/donnees/note1juin2008.txt",
header = TRUE)
n1j$groupe <- factor(n1j$groupe, levels = c("zero", "un", "deux"),
ordered = TRUE)
col <- c("red2", "orange","green2")
xlab <- "Nombre de devoirs rendus"
ylab <- "Note /20"
par(mfrow = c(2,2), lend = "butt", oma = c(0,0,3,0), mar = c(5,4,0,2)+0.1)
barplot(table(n1j$groupe), las = 1, ylab = "Nombre d'etudiants",
col = col, xlab = xlab)
boxplot(n1j$note1 ~ n1j$groupe, col = col, ylim = c(0, 20), las = 1,
ylab = ylab, varwidth = TRUE, notch = TRUE,
xlab = xlab, xlim = c(0,4))
abline(h = 10, col = "blue", lty =2)
mtext(paste("Resultats de l'examen du 01-JUN-08 (n =", nrow(n1j), "etudiants)"),
side = 3, outer = TRUE, line = 1, cex = 1.5)
rug(jitter(n1j[n1j$groupe == "zero", "note1"]), side = 2, col = col[1])
rug(jitter(n1j[n1j$groupe == "deux", "note1"]), side = 4, col = col[3])
library(vioplot)
myplot <- function(h = 1){
plot.new()
plot.window(xlim = c(0,4), ylim = c(0,20))
wex <- 3*table(n1j$groupe)/nrow(n1j)
vioplot(n1j[n1j$groupe=="zero", "note1"], col = col[1], add = TRUE,
at = 1, wex = wex[1], h = h)
vioplot(n1j[n1j$groupe=="un", "note1"], col = col[2], add = TRUE,
at = 2, wex = wex[2], h = h)
vioplot(n1j[n1j$groupe=="deux", "note1"], col = col[3], add = TRUE,
at = 3, wex = wex[3], h = h)
abline(h = 10, col = "blue", lty =2)
axis(1, at = 1:3, labels = c("zero", "un","deux"))
axis(2, las = 1)
rug(jitter(n1j[n1j$groupe == "zero", "note1"]), side = 2, col = col[1])
rug(jitter(n1j[n1j$groupe == "deux", "note1"]), side = 4, col = col[3])
title(xlab = xlab, ylab = ylab)
}
myplot()
myplot(0.25)ce qui nous donne :
Pour moi le plus surprenant est qu'il n'y ait que 35 % des étudiants qui aient profité de la possibilité de rendre 2 devoirs, cela fait une proportion de touristes inhabituellement élevée, même pour une première année de licence.
Amicalement,
Jean
-
Lorraine Bauer
- Messages : 67
- Enregistré le : 18 Nov 2008, 12:06
Jean, je n'ai qu'un mot : MA-GNI-FIQUE !!
Tes graphiques sont vraiment très beaux, je garde précieusement le code pour très sûrement m'en servir lors d'une prochaine présentation. Je ne connaissais pas cette fameuse library(vioplot), je vais regarder cela de plus prêt...
Merci de m'avoir consacré un peu de ton temps.
Amitié
Lorraine
Tes graphiques sont vraiment très beaux, je garde précieusement le code pour très sûrement m'en servir lors d'une prochaine présentation. Je ne connaissais pas cette fameuse library(vioplot), je vais regarder cela de plus prêt...
Merci de m'avoir consacré un peu de ton temps.
Amitié
Lorraine
-
jean lobry
- Messages : 733
- Enregistré le : 17 Jan 2008, 20:00
- Contact :
Bonjour Lorraine,
bienvenue au club :-)
Est ce que tu pourrais donner plus de détails sur l'origine des données (nature de l'épreuve, parcours, Université). Ce sont des PV d'examens publics donc il n'y a pas de problème de confidentialité. En re-regardant les graphiques je trouve que ces données illustrent assez bien le problème des boîtes à moustaches en cas de multimodalité. Je les utiliserais bien en enseignement à l'occasion.
Amicalement,
Jean
bienvenue au club :-)
Est ce que tu pourrais donner plus de détails sur l'origine des données (nature de l'épreuve, parcours, Université). Ce sont des PV d'examens publics donc il n'y a pas de problème de confidentialité. En re-regardant les graphiques je trouve que ces données illustrent assez bien le problème des boîtes à moustaches en cas de multimodalité. Je les utiliserais bien en enseignement à l'occasion.
Amicalement,
Jean
-
Lorraine Bauer
- Messages : 67
- Enregistré le : 18 Nov 2008, 12:06
Bonjour Jean,
Je suis désolé, mais il m'est impossible de fournir trop de détails sur ces données. Je sais que formellement j'ai le droit de le faire, mais cela ne plairait pas à l'enseignant concerné qui a déjà eu pas mal d'ennuis avec sa matière, les collègues et les étudiants. J'espère que tu me comprendras.
Bien à toi
Lorraine
PS : Mais bien évidemment tu peux disposer du jeu de données tel que je l'ai présenté ici comme bon te semblera et tant mieux si tu peux l'utiliser dans un enseignement.
Je suis désolé, mais il m'est impossible de fournir trop de détails sur ces données. Je sais que formellement j'ai le droit de le faire, mais cela ne plairait pas à l'enseignant concerné qui a déjà eu pas mal d'ennuis avec sa matière, les collègues et les étudiants. J'espère que tu me comprendras.
Bien à toi
Lorraine
PS : Mais bien évidemment tu peux disposer du jeu de données tel que je l'ai présenté ici comme bon te semblera et tant mieux si tu peux l'utiliser dans un enseignement.
Retourner vers « Questions en cours »
Qui est en ligne
Utilisateurs parcourant ce forum : Google [Bot] et 1 invité